nextstep 교욱과정
작년 3월, 그러니까 1년 반전 쯤… 이쪽 업계에서는 유명하신 박재성(자바지기)님이 하시는 교육과정을 들은적이 있었다.
교육과정명은 클린코드를 위한 TDD, 리팩토링 with Java 이었는데, 과정은 대충 이러했다.
매주 금요일 3시간의 수업을 진행한다(총 5주)
매주 금요일 오후 7시 반에 강남역에 모여서 수업을 진행한다.
수업 내용은 대부분 OOP, TDD, refactoring 에 대한 내용이었고, 가끔씩 재성님의 인생 철학(!)을 얘기해주시기도 하신다.
수업 내용은 아주 유익하고, 인생 철학 또한 아주 유익하다 ㅋㅋㅋ
수업과 별개로 과제를 진행한다
이 과제가 교육과정의 핵심이다.
프로그래밍 언어로 자동차 경주 게임, 로또, 사다리 게임 등을 직접 구현하는 과제이다(출력은 콘솔로 한다).
단순히 구현하는 것이 아니라, 교육과정 중에 배운 OOP, TDD, refactoring 을 열심히 사용(?)하여 구현해야 한다.
그리고 각 과제마다, 담당 코드 리뷰어들이 있다.
(리뷰어는 이미 이 과정을 수료하신 분들로 구성되어 있다.)
하나의 과제는 여러 step 들로 구성되어 있으며, step 별 요구사항을 완료하여 PR 을 보내면 리뷰어가 리뷰를 해주고, approve 가 되면 다음 step 으로 넘어가게 되는 구조이다.
이렇게 총 5개(1개는 optional)의 과제를 완료하면 교육과정을 수료할 수 있게 된다.
어렵다 어려워
매번 서비스 메서드에 모든 로직을 다 떄려박던 나같은 트랜잭션 스크립터(?)에게 이 과제는 매우 어려웠었다.
지금까지 내가 해오던 코딩과는 너무 달랐기 때문이었다.
어떤 기준으로 객체를 설계해야할지, 객체끼리는 어떻게 메시지를 주고 받아야할지, 테스트는 제대로 짜고 있는지…
그야말로 혼란스러웠다.
몇시간동안 한줄도 못 짜고 머리를 싸매며 고통스러워 했었던적도 한두번이 아니었던 것 같다.
그래도 매일 고민하고, 리뷰어님들의 아주아주 정성스러운 피드백들을 받다보니 시간이 지날수록 조금씩 나아지는 내 모습을 발견할 수 있었다.
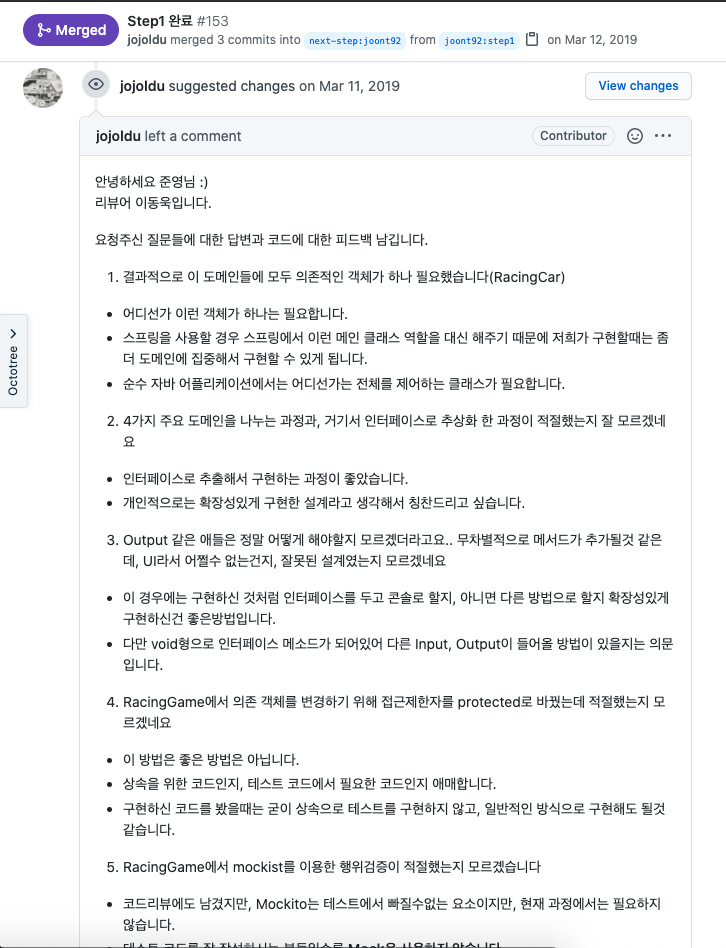
그저 빛…
결과적으로 5주 동안 필수 과제 4개를 전부 완료하고, 한 단계 더 성장한 모습으로 이 과정을 수료할 수 있었다.
이제는 실전
회사로 돌아왔다(교육과정 듣는다고 회사를 안간것은 아니었지만…).
회사 코드를 봤다.
트랜잭션 스크립트 패턴이 많고, 테스트도 많이 없다. 개선해야 할 부분이 많아 보인다.
하지만 코드 자체가 워낙 양이 많고 복잡하며, 다른 코드나 시스템끼리 복잡하게 의존되는 부분이 많아서 어디서부터 어떻게 시작해야할지 정하기가 힘들었다.
그래도 훈련소까지 갔다왔는데… 그냥 포기할수는 없었다.
기존에 존재하던 코드들에 대해 테스트를 작성하기 시작했고, 테스트 작성이 완료되고나니 조금씩 리팩토링 하는것이 가능했다.
그렇게 하나의 프로젝트를 전반적으로 리팩토링했다.
굉장히 뿌듯했다.
새로운 프로젝트를 들어갔을때에도, 클린코드에 대한 끈을 놓지 않으려고 했다.
항상 테스트를 작성했으며, 객체 설계에 대해 매번 고민하고 작성했다.
그렇게 1년 정도 실전에서 훈련한 결과, 확실히 코드 자체가 작년에 비해 많이 달라진것을 느끼고 있다.
아직 갈 길은 많이 멀었지만, 작년에 이 과정을 듣지 못했다면 아직까지 나는 얽히고 섥힌 코드들을 유지보수하느라 고통받고 있지 않았을까 싶다.
nextstep 멘토링
이 교육에는 수업 이후에 멘토링을 해주는 과정이 추가적으로 포함되어 있다.
멘토링은 이 과정을 수료한 수강자에 한해서 모두 제공된다.
단순히 수업을 듣는다고 수료가 되는것이 아니라, 필수과제 4개의 과제를 모두 제출해 통과해야만 수료가 된다.
멘토링에서 해주는 내용은 아래와 같다.
- 이력서 검토 및 피드백
- 온라인, 오프라인 모의 면접
- 추천
어쩌다보니 나도 이번에 이직 시기가 되어서, 멘토링을 신청하게 되었다.
이력서 검토 및 피드백
일단 자유 포멧으로 이력서를 작성해 전달해주면, 이력서를 전체적으로 점검하고 피드백을 작성하여 전달해주신다.

이런식으로 전달해주신다. 매우 좋다!!!
전달받은 피드백을 적용해서 이력서를 다시 전달해드리면 또 추가적으로 피드백을 주시게 되고, 이런식으로 몇번 왔다갔다 하면서 이력서를 전체적으로 다듬어가는 과정이다.
이 과정에서 확실히 처음에 비해 이력서가 매우 나아지는 과정을 경험했다.
온라인 모의 면접
처음에는 그냥 화상 회의라고 하셔서 부담없이 들어갔는데… 온라인 모의 면접이었다😅
이력서를 기반으로 꼼꼼하게 질문해주시고, 이 질문이 어떤 의도였는지, 내 대답이 어땠으면 좋았을지에 대해 바로 바로 피드백 해주신다.
그리고 다음 오프라인 면접 날짜를 잡고, 그 날짜까지 추가로 더 준비해오면 좋을 것들에 대해 숙제(!)를 내주신다.
개인적으로 피드백 해주시는 내용들이 도움이 많이 되었고, 내 스스로 내가 한 일들에 대해 제대로 정리되어 있지 않았다는 사실을 깨달을 수 있었다.
오프라인 모의 면접
온라인 면접 후, 딱 1주일 뒤에 오프라인 모의 면접을 진행했다.
오프라인 모의 면접은 잠실역에 있는 우형 사무실에서 진행했다.
총 1시간 정도 진행되며, 온라인 면접처럼 바로 피드백을 주지 않고 실제 면접과 동일한 분위기로 모의 면접을 진행하였다.
그리고 오프라인인 만큼 내가 수행했던 프로젝트에 대해 화이트보드에 그려가며 설명하는 과정들이 많았다.
확실히 모의면접을 진행하고나니 자신감도 붙고, 앞으로 어떤 부분들을 더 준비해야할지 더 잘 알게 되었다.
추천
이후에는 추천이다.
이력서, 모의면접 과정을 다 진행하고 난 후에 통과가 되면 nextstep 쪽에서 연계된 기업들에 한해 추천을 해준다.
단순히 내 이력서만 전달해주시는 것이 아니라, 교육과정과 멘토링 진행할 때의 내 모습을 기반으로 직접 추천서를 작성해서 같이 전달해주신다.
그래서 결과는?
모의면접 진행이 끝난 후 실제 이력서를 내고 면접을 진행하였고, 최종적으로 원하던 기업에 합격하여 다음주에 입사하게 된다.
면접 과정에서 nextstep 에서 받았던 멘토링 과정이 도움이 많이 되었다.
평소에 갈증이 많은 개발자라면 nextstep 의 교육 과정을 들어보는 것을 추천한다.

{kind=link}