JPA는 자바에서 기본으로 제공하는 Collection, List, Set, Map 컬렉션을 지원하고, 아래와 같은 상황에서 컬렉션을 사용할 수 있다.
- @OneToMany, @ManyToMany 를 사용해서 일대다나 다대다 관계를 매핑할 때
- @ElementCollection 을 사용해서 값 타입을 하나 이상 보관할 때
하이버네이트는 엔티티를 영속상태로 만들 때 컬렉션 필드를 하이버네이트에서 준비한 컬렉션으로 감싸서 사용한다.
이는 하이버네이트가 컬렉션을 효율적으로 관기하기 위함이다.
하이버네이트는 본 컬렉션을 감싸고 있는 내장 컬렉션을 생성한 뒤, 이 내장 컬렉션을 사용하도록 참조를 변경한다.
Collection, List
중복을 허용하는 컬렉션이다.
하이버네이트에서 PersistentBag으로 래핑된다. 사용할 때는 ArrayList로 초기화하면 된다.
1 | (mappedBy = "parent") |
중복을 허용하는 특성때문에 겍체를 추가할때 아무 조건검사가 필요없으므로, 지연로딩이 발생하지 않는다.
하지만 엔티티가 있는지 체크하거나 삭제할 경우 eqauls로 비교해야 하므로 지연로딩이 발생한다.
1 | children.add(child); // no action |
Set
중복을 허용하지 않는 컬렉션이다.
하이버네이트에서 PersistentSet으로 래핑된다. 사용할 때는 HashSet으로 초기화하면 된다.
1 | (mappedBy = "parent") |
중복을 허용하지 않으므로 객체를 추가할 때 마다 equals 메서드로 같은 객체가 있는지 비교한다. 즉 add 메서드만 수행해도 지연로딩이 발생한다.
참고로 HashSet은 해시 알고리즘을 사용하므로 equals와 hashCode를 같이 사용한다.
1 | children.add(child); // eqauls + hashCode |
List + @OrderColumn
순서가 있는 복수형 컬렉션을 의미하는데, 데이터베이스에 순서값을 저장해서 조회할 때 사용한다는 의미이다.
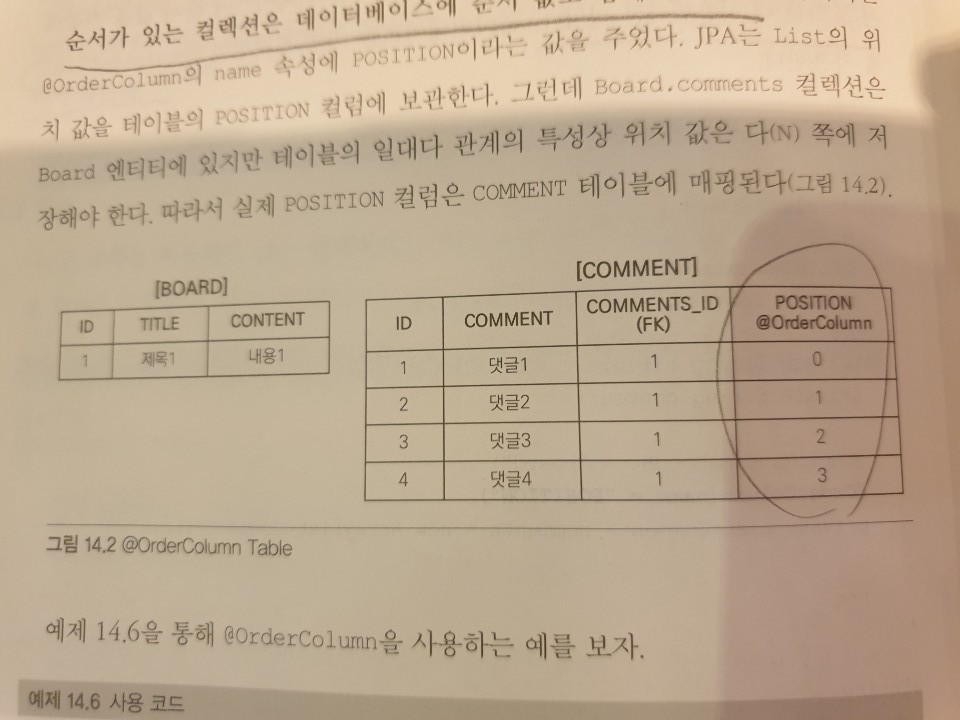
위처럼 데이터베이스에 순서값을 함꼐 관리하는 테이블에 사용된다.
1 |
|
List의 위치(순서)값을 POSITION이라는 컬럼에 저장하게 되는것이고, 이는 일대다 관계의 특성에 따라 다(N)쪽에 저장하게 된다.
아래는 사용예제이다.
1 | Board board = new Board("title", "content"); |
어떻게보면 위치값을 알아서 관리해주니 편해보이지만 사실은 실무에서 사용하기에는 단점이 많다.
- Comment가 POSITION의 값을 알 수 없다. Board에서 관리되기 때문이다.
이러한 특징때문에 위의 명령을 수행하면 comment1, comment2 insert 후에 POSITION 값을 수정하는 update가 2번 추가로 발생한다(ㄷㄷ) - 요소가 하나만 변경되도 모든 위치값이 변경된다. 예를들어 첫번쨰 댓글을 삭제하면 그 뒤의 댓글들의 POSITION-- 하는 update가 댓글의 개수만큼 발생한다.
- 중간에 POSITION 값이 없으면 null이 저장된다. 예를들어 강제로 0,1,2의 POSITION 값을 0,2,3으로 변경하면 1번 위치에 null이 보관된 컬렉션이 반환된다. 이러면 NullPointerException이 발생한다.
@OrderBy
ORDER BY 절을 이용해서 컬렉션을 정렬하는 방법이다. @OrderColumn 처럼 순서용 컬럼을 매핑하지 않아도 된다.
1 |
|
이렇게 하면 comments를 초기화 할 때 명시해놓은 ORDER BY 구문이 같이 수행되어 순서가 보장된다.
사용하는 컬럼명은 JPQL 때처럼 엔티티의 필드를 대상으로 한다.