kubernetes란?
구글이 2014년에 발표한 컨테이너 오케스트레이션 도구이다
컨테이너 오케스트레이션 도구란
많은 수의 컨테이너를 협조적으로 연동시키기 위한 통합 시스템을 말한다
도커 등장 이래로 많은 오케스트레이션 도구가 나왔지만(mesos, ECS, Swarm 등),
쿠버네티스가 가장 강력한 끝판왕으로 등장함에 따라 현재는 사실상 표준이 된 상태이다
많은 클라우드 플랫폼에서도 쿠버네티스를 연동하여 사용할 수 있는 기술을 제공한다
GCP는 GKE, AWS는 EKS, 애저는 AKS
로컬에서 kubernetes 띄우기
예전에는 로컬에서 kubernetes를 띄우려면 minikube 를 이용해야 했는데
minikube는 기존에 도커를 위해 띄워진 VM에 쿠버네티스를 띄우는 것이 아니라 새로운 VM(dockerd)를 띄우는 방식이므로 조금 까다로운 면이 있었다
하지만 요즘에는 윈도우/macOS용 도커에서 쿠버네티스 통합 기능을 제공해주므로 이를 사용하여 간단하게 쿠버네티스를 구축할 수 있다
대신 minikube 에 자동으로 설치되어 있는 대시보드 같은것은 추가로 설치해줘야 하는 불편함은 있다
mac에서 kubernetes 설치는 kubernetes 탭의 Enable Kubernetes만 클릭해주면 된다
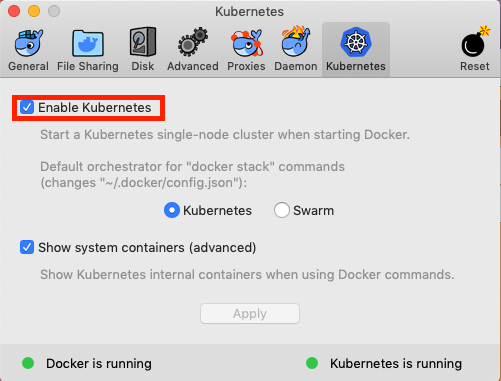
그리고 쿠버네티스 API를 실행하기 위한 명령행 도구인 kubectl도 설치해준다
https://kubernetes.io/docs/tasks/tools/install-kubectl/
kubernetes 주요 개념
쿠버네티스 내에는 매우 다양한 리소스들이 존재하고, 이 리소스들이 클러스터내에서 서로 연동하고 협조하면서 컨테이너 시스템을 구성하는 형태이다
하나의 쿠버네티스 환경 자체를 클러스터라고 부른다
노드
쿠버네티스 내에 떠있는 호스트들(가상머신이나 물리적 서버머신)이다
이중에서도 마스터 노드와 일반 노드들로 나뉘는데, 마스터 노드에는 쿠버네티스 클러스 전체를 관리하기 위한 관리 컴포넌트들이 자리하는 곳이고, 이 관리 컴포넌트들에 의해 일반 노드들로 컨테이너들이 오케스트레이션 되는 구조이다
마스터 노드에 들어가는 관리 컴포넌트들의 종류는 아래와 같다
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- etcd
마스터 노드에는 이 관리 컴포넌트 외에 다른 컴포넌트(Pod)들은 들어갈 수 없다
여기까지가 기본적인 개념이고, 이제부터 쿠버네티스의 주요 리소스에 대해 설명하겠다
아래는 간단한 설명이며, 상세한 설명은 조대협님의 블로그를 보는 것이 좋을 것 같다
오브젝트
쿠버네티스에서 가장 중요한 부분은 오브젝트라는 개념인데, 이 오브젝트는 크게 기본 오브젝트와 컨트롤러로 나뉜다
기본 오브젝트는 리소스들의 가장 기본적인 구성 단위이며, 컨트롤러는 이 기본 오브젝트들을 생성하고 관리하는 기능을 가진 애들을 말한다
기본 오브젝트의 종류는 아래와 같고
- 파드
- 서비스
- 볼륨
- 네임스페이스
컨트롤러의 종류는 아래와 같다
- 레플리카 셋
- 디플로이먼트
- 스테이트풀 셋
- 데몬 셋
- 잡
참고로 아래에서 설명하겠지만, 이 오브젝트들은 모두 논리적인 단위이다
각 노드들에 생성된 수많은 도커 컨테이너, 네트워크 인터페이스들을 쿠버네티스가 논리적인 단위로 묶어서 Pod, Service, namespace 등의 개념으로 제공하게 되는 것이다
이 오브젝트에 중요한 속성이 있는데, 바로 스펙과 상태이다
스펙은 우리가 직접 설정파일 같은 것으로 작성해서 전달해줘야 하는것으로써, 오브젝트가 어떤 상태가 되어야 한다고 작성한 것을 말한다
아래는 스펙의 간단한 예제이다
1 | apiVersion: v1 |
busybox 이미지를 가진 container가 하나 들어가있는 pod를 띄워야한다고 스펙에 명시했다
이 스펙을 보고 쿠버네티스는 오브젝트를 생성하게 될 것이며, 이 오브젝트에 대한 상태는 쿠버네티스에 의해 제공되게 된다
그리고 쿠버네티스는 이 오브젝트의 상태가 우리가 원한 상태와 일치하도록 계속 관리해주는 역할을 수행하게된다
원하는 상태를 직접 명시하지는 않았지만, 아마도 RUNNING 을 말하는거겠지…
기본 오브젝트 - Pod
쿠버네티스의 가장 기본적인 배포 단위(컨테이너)이다
우리가 알고있는 도커 컨테이너와는 조금 다른게, 하나의 Pod는 하나 이상의 컨테이너를 포함할 수 있는 구조이다
즉 웹서버를 구성한다고 할 때 nginx pod, spring-boot pod, mysql pod 를 각각 띄워야 하는 것이 아니라 이 컨테이너들을 모두 하나의 pod에 넣을 수 있다는 의미이다
위의 오브젝트의 스펙을 설명하는 부분에서 Pod의 설정파일 예시를 작성했는데, 보다시피 spec에 containers 로 여러 컨테이너를 받을 수 있게 되어있다
하나의 Pod는 하나의 노드에만 배치될 수 있다
Pod 내의 컨테이너가 각각 다른 노드에 배치될 수 없다
이러한 특징 때문에,
쿠버네티스 내에서 Pod를 띄울경우 내부의 컨테이너가 다 떠야 Pod 의 상태가 RUNNING 으로 표시되고(e.g. 2/2),
Pod 에 접근하고자 할 경우 -c 옵션으로 접근할 컨테이너를 지정해줘야 한다
1 | $ kubectl exec -it myapp-pod /bin/bash -c myapp-container |
그리고 추가로,
Pod에는 관심사를 합칠 수 있다는 장점(컨테이너들을 여러개 묶어서 배포할 수 있으므로) 외에도 추가적인 장점이 존재한다
첫째로, Pod 내의 컨테이너들은 서로 IP와 Port를 공유한다
기존에 docker-compose로 띄웠던 컨테이너들이 서로 이름으로 참조했던 방식이 아닌, 서로 localhost로 통신할 수 있는 방식이다
즉, 1개의 Pod 내에 만약 spring-boot, mysql이 있다고 한다면 각자 서로를 localhost:8080, localhost:3306 으로 참조할수 있게 되는 것이다
각자의 IP를 가지는 컨테이너들이 어떻게 localhost로 통신할 수 있을까?
둘째로, Pod 내부의 모든 컨테이너가 공유하는 볼륨을 설정할 수 있다
즉 Pod 내부의 모든 컨테이너는 그 볼륨에 접근할 수 있고, 그 컨테이너끼리 데이터를 공유하는 것을 허용하게 되는 것이다
기본 오브젝트 - 서비스
아래에서 다시 설명하겠지만, Pod의 경우 kubernetes 에서 가장 작은 단위의 리소스라 삭제되거나 추가되는 행위가 잦은 리소스이다(scalable)
문제는 매번 삭제되고 추가될 때 마다 IP가 랜덤하게 새로 부여된다는 것이다
이러한 상황에서는 고정된 엔드포인트로 호출하는 것이 어려워진다
또한 Pod의 경우 보통 1개로 운영하지 않고, 여러개의 Pod을 띄워서 로드밸런싱을 제공해줘야 한다
즉, 이러한 역할을 해주는 리소스가 Pod들 앞단에 하나 더 존재해야하는데, 서비스가 이러한 역할을 한다
서비스는 지정된 IP로 생성이 가능하고, 여러 Pod를 묶어서 로드 밸런싱이 가능하며, 고유한 DNS 이름을 가질 수 있다
서비스가 Pod 들을 묶을 때는 레이블과 셀렉터 라는 개념을 사용하는데, 아래의 스펙을 보면 직관적으로 이해할 수 있을 것이다
1 | apiVersion: v1 |
보다시피 selector 로 app: myapp 이라고 선언해놓았는데, 이는 app: myapp 이라는 레이블을 가진 Pod 들을 선택해서 my-service 라는 서비스로 묶겠다는 의미이다
그렇다면 label은 어떻게 설정하는가?
위의 Pod 를 설정할 때 metadata에 label: myapp 이라는 부분을 봤을 것이다
1 | apiVersion: v1 |
이 부분이 리소스에 label을 설정하는 부분이다
label은 여러개 설정할 수 있다
이제 이렇게 서비스를 정의했으니 이 서비스를 통해 Pod 에 접근할 수 있어야 할 것이다
이는 서비스를 생성할 때 지정하는 타입에 따라 방식이 나뉜다
쿠버네티스에서 지원하는 서비스의 타입들은 아래와 같다
-
ClusterIp
디폴트 설정으로, 서비스에 내부 IP(Cluster IP)를 할당한다
그러므로 클러스터 내에서는 접근이 가능하지만, 클러스터 외부에서는 접근이 불가능하다
클러스터 내의 컨테이너로 들어간 뒤curl http://my-service[:80]를 호출하면 myapp 레이블을 가진 pod의 80포트로 연결될 것이다(targetPort 지정가능, 지정하지 않을 시 port와 동일하게 설정) -
NodePort
Cluster IP 로 접근가능하면서 모든 노드의 IP와 포트를 통해서도 접근이 가능하게 된다1
2
3
4
5
6
7
8
9....
spec:
selector:
app: myapp
type: NodePort
ports:
- protocol: TCP
port: 80
nodePort: 31111클러스터 내에서
<내부IP>:<포트>으로도 접속 가능하고, 외부에서<NodeIP>:<NodePort>로도 접근 가능하다모든 Node의 포트가 열리고, 해당 서비스로 연결된다
30000 ~ 32767 까지 사용 가능
노드의 IP가 바뀔 수 있는 부분을 처리해줘야함
보통 ingress랑 같이 씀
ingress랑 같이 쓰면 해결됨
api gateway 붙이기 싫을 때 ingress를 쓴다? -
LoadBalancer
보통 클라우드 서비스에서만 설정 가능한 방식으로, 외부 IP를 가지고 있는 로드밸런서를 할당한다
외부 IP를 가지고 있기 때문에 외부에서 접근이 가능하다
클라우드 서비스 내에서 외부 IP가 할당된 로드밸런서를 생성하고 서비스에 연결시키는 구조
서비스 자체에 로드밸런싱 기능이 있는데, 왜 굳이 로드밸런서를 할당시키는지? -
ExternalName
외부 서비스를 쿠버네티스 내부에서 호출하고자 할 떄 사용할 수 있다
클러스터 내의 Pod들이 클러스터 밖에 있는 서비스(예를 들면 RDS)를 호출하려면 NAT 설정 등 복잡한 설정이 필요한데, 서비스를 externalName 타입으로 설정하면 이를 간단하게 해결 가능하다1
2
3
4
5
6
7
8
9apiVersion: v1
kind: Service
metadata:
name: my-service-for-rds
spec:
selector:
app: myproxy
type: ExternalName
externalName: xxxx-rds.amazonaws.com이렇게 설정하면 클러스터 내의 Pod 들이 이 서비스를 호출할 경우
xxxx-rds.amazoneaws.com으로 포워딩해주게 된다(일종의 프록시 역할)
기본 오브젝트 - 볼륨
도커로 볼륨을 연결할때를 생각해보면, 볼륨은 도커 컨테이너가 생성된 호스트에 위치해야 했다
하지만 쿠버네티스의 특성상 Pod가 여러 호스트(노드)를 교차하면서 배포되므로, 이러면 너무 번거롭다
쿠버네티스는 이를 해결하기 위해 PersistentVolume, PersistentVolumeClaim 이라는 것을 제공한다
간단히 말해 PersistentVolume은 쿠버네티스에 지정한 물리 디스크이고, PersistentVolumeClaim은 그 PersistentVolume과 Pod를 연결할 수 있게 해주는 개념이다
자세한 내용은 https://bcho.tistory.com/1259 를 참고한다
PersistentVolume 외에도 쿠버네티스는 다양한 볼륨을 지원한다
https://kubernetes.io/docs/concepts/storage/volumes/
기본 오브젝트 - 네임스페이스
쿠버네티스 클러스터내의 논리적인 분리단위이다
네임스페이스별로 리소스들을 나눠서 관리할 수 있고, 접근권한, 리소스 할당량 등을 설정할 수 있다
컨트롤러 - ReplicaSet
알다시피 어느정도 규모가 되는 어플리케이션을 구축하려면 하나의 Pod로는 안되고, Pod를 여러개 실행해 가용성을 확보해야 한다
이럴때 사용하는 것이 RelicaSet이다
ReplicaSet는 똑같은 정의를 갖는 Pod를 여러개 생성하고 관리하기 위한 리소스이다
1 | apiVersion: apps/v1 |
보다시피 크게 replicas, selector, template 3가지의 파트로 구성된다
- replicas
ReplicaSet에 의해 관리될 Pod의 개수이다
설정된 값보다 Pod의 수가 적으면 추가로 띄우고, Pod의 수가 더 많으면 남는 Pod를 삭제한다 - selector
ReplicaSet으로 관리할 Pod를 선택한다
현재는 label을 기반으로 select 하고 있다service 의 selector 와 문법이 달라서 혼동될 수 있는데, 그냥 지원되지 않는 것이라고 한다(deployment 는 됨)
https://medium.com/@zwhitchcox/matchlabels-labels-and-selectors-explained-in-detail-for-beginners-d421bdd05362 - template
Pod를추가로 띄울 때어떻게 만들지에 대한 Pod 정보를 정의해놓은 부분이다
새로 생성된 Pod도 selector에 의해 선택되어야 하므로 selector의 label과 동일하게 맞춰줘야 한다
아래는 ReplicaSet에 대해 조금 주의(?)할 부분들이다
- ReplicaSet 생성 시 label이 일치하면 기존에 떠있는 Pod 들도 같이 ReplicaSet로 묶이는데, 이 Pod들이 template에 있는 Pod의 형태와 않더라도 삭제되지 않음에 주의해야 한다
e.g. 기존에
app: reverse-proxy레이블의 apache Pod가 떠있는 상태에서,
selector = app: reverse-proxy, template = nginx의 ReplicaSet을 생성하면 기존의 apache Pod는 삭제되지않고 같은 ReplicaSet이 된다 - selector 가 Pod 들을 묶는 기준이니까, 기존에 ReplicaSet가 띄워진 상태에서 selector 를 바꾸게 되면 기존의 Pod 들은 삭제되지 않고 남아있게 되나?
ReplicaSet으로 떠있는 상태에서 selector를 바꾸게 되면 문법적으로 오류가 발생한다
ReplicaSet에 대한 메타정보(떠있는 Pod들과 매핑 등)이 마스터 노드 어딘가에… 저장되어서 그것으로 판단하는 것 같다
컨트롤러 - Deployment
ReplicaSet 보다 상위에 있는 개념으로 ReplicaSet 배포의 기본 단위가 되는 리소스이다
아래와 같은 관계이다

쿠버네티스는 이 Deployment를 단위로 애플리케이션을 배포한다
실제 운영에서는 ReplicaSet을 직접 다루기보다는 Deployment를 통해 배포하는 경우가 대부분이다
설정은 ReplicaSet와 거의 동일하게 작성한다
1 | apiVersion: apps/v1 |
Deployment의 특징은 리비전을 사용해 배포를 관리할 수 있다는 점이다
Deployment를 생성한 뒤 리비전을 확인해본다
1 | $ kubectl apply -f deployment.yml --record # 어떤 kubectl을 실행했는지 남기기 위함 |
결과로는
REVISION=1값이 출력됨을 볼 수 있다
이 리비전값은 아래와 같은 특성이 있다
- replicas 의 값을 바꿔도 리비전값이 올라가진 않는다
- replicaSet 컨테이너의 이미지를 바꾸고 적용하면 리비전값이 올라간다
리비전을 올리기 위해 아래와 같이 컨테이너 이미지를 바꾸고
1 | containers: |
deployment를 다시 적용하면 리비전값이 올라감을 볼 수 있다
1 | $ kubectl rollout history deployment echo |
1 | $ kubectl get pods --selector app=frontend |
이렇게 리비전으로 관리하게 됨으로써 Deployment를 롤백이 가능하게 된다
$ kubectl rollout undo deployment frontend
Pod를 확인해보면 바로 직전 리비전으로 롤백되고 있음을 볼 수 있다(바로 직전만 가능한 듯 하다)
롤백되면 리비전이 다시 1로 돌아가는 것이 아니라, 3으로 올라간다
리비전은 최대 10까지 가능한 것 같다
참고 :