이번에는, 프로그램을 만들때 중요하지만 대부분의 개발자가 귀찮아 하는 예외처리에 대해 알아보겠습니다.
잘못된 예외처리는 찾기 힘든 버그를 낳을 수 있고, 더욱 난처한 상황을 만들 수 있으므로 항상 신경써줘야 합니다.
잘못된 예외처리
예외 블랙홀1
1 | try { |
예외발생을 무시하고 정상적인 상황인 것 처럼 다음으로 넘어가겠다는 분명한 의도가 있지 않은 이상 절대 하면 안됩니다.
위는 예외가 발생했는데 그것을 무시하고 진행하겠다는 의미인데, 이렇게 해봐야 최종적으로 프로그램에 오류가 발생할 것입니다.
하지만 그때는 이미 되돌리기엔 늦어버리고, 원인을 찾기도 힘듭니다.
예외 블랙홀2
1 | try { |
예외 블랙홀1과 별다를게 없습니다. 이는 그냥 로그를 출력한 것이지 예외를 처리한 것이 아닙니다.
예외 블랙홀 처럼 굳이 예외를 잡아서 조치를 취할게 없으면 그냥 잡지를 말아야 합니다.
차리라 throws로 책임을 전가해버리는 것이 낫습니다.
무차별 throws
말했다고 바로 나오네요…
1 | void method1() throws Exception{ |
method3을 개발한 개발자는, 예외를 잡아봤자 처리할 것도 없고 매번 발생가능한 예외를 찾아내서 throws로 선언하기 귀찮아서 그냥 최상위 예외인 Exception을 throws로 던져버리고 있습니다.
method2를 개발한 개발자도 똑같은 행위를 하고 있네요.
일단은, 이 처리 자체가 위의 예외 블랙홀 보다는 낫지만 결국 무책임한 처리이긴 합니다.
그리고 만약 method1을 개발하는 개발자가, 발생하는 예외를 처리하려 했다고 합시다.
그래서 method2를 봤더니… 왠열 걍 throws Exception이네요.
뭐지… 하고 method3까지 들어갔더니 또 throws Exception입니다.
이건 뭐… 왜 예외가 발생하는지 하나하나 다 까봐야겠네요 ㅡㅡ
이처럼 무차별 throws는 정확한 예외상황을 제공해주지 않는 무책임한 예외처리 기법입니다.
예외처리 방법
일단 예외를 처리하는 일반적인 방법은 아래와 같습니다.
예외 복구
예외 상황을 파악하고 문제를 해결하여 정상 상태로 돌려놓는 방법입니다.
말그대로 예외를 catch로 잡아서 적절한 처리를 진행하는 의미죠. 예외 블랙홀은 절대 예외 복구가 아닙니다.
예외 회피
예외를 직접 처리하지 않고 throws를 통해 호출한 쪽으로 던지거나,
catch로 잡아서 로그를 찍고 throw로 다시 던지는 방법입니다. 무차별 throws가 되지 않도록 주의해야 합니다.
예외 전환
예외 포장
예외 회피 처럼 호출한 쪽으로 예외를 던지는 것이긴한데, 그냥 던지는 것이 아니라 좀 더 의미있는 예외로 변환하여 던집니다.
1 |
|
예를 들어 위와 같은 테스트 코드는 분명 에러를 발생시킬 겁니다.
똑같은 데이터를 2번 넣고 있기 때문에 기본키 제약조건에 걸리거든요.
근데 중요한건, 여기서 발생하는 예외가 SQLException 이라는 겁니다.
SQLException은 SQL 관련해서 오류만 낫다하면 항상 발생하는 매우 모호한 Exception 입니다.
굳이 기본키 제약조건에 걸려 데이터가 중복되는 상황만이 아닌 모든 SQL 관련 오류에 발생하는 Exception 이라는 거죠.
(JDK 1.6부터 조금씩 변화하고 있지만 아직 대부분이 SQLException으로 처리되고 있습니다.)
이래서는 dao의 add를 호출한 쪽에서 예외를 처리하는것도 애매해집니다.
그냥 SQLException이라고 오면 이게 무슨 예외인지 어찌 알겠습니까… 무차별 throws 기억나시죠? 비슷합니다.
그래서 예외전환을 통해 DAO의 add를 아래와 같은 방식으로 전환해주는 겁니다.
1 | public void add(User user) throws DuplicateUserIdException{ |
모호한 SQLException이 아니라 DuplicateUserIdException과 같은 좀 더 확실한 의미의 예외로 전환해서 던져주는 겁니다.
이로써 호출하는 쪽에서 예외처리 또한 수월해지게 됩니다.
getErrorCode
JDBC는 데이터 처리중에 발생하는 다양한 예외를 그냥 SQLException 하나에 담아버립니다.
getErrorCode는 SQLException에 정의된 메서드로써, 예외가 발생된 에러 코드를 반환해줍니다.
해당 코드를 통해 발생한 SQLException에 대해 적절한 처리가 가능해집니다.
하지만 에러코드라는게 DB 벤더마다 각각 다르므로 getErrorCode 메서드를 통해 DB에 독립적인 예외처리는 힘들다는 단점이 있습니다…
위에서 비교한 중복코드 라는 것이 DB 마다 다 제각각 이라는거죠.
SQLException에서 DB에 독립적인 예외처리를 위해 getSQLState라는 메서드를 제공하고는 있지만,
실상 각 DB 제조사들은 이 상태 코드를 제대로 작성해주지 않은 경우가 많습니다. ㅠ.ㅠ
그래서 DuplicateUserIdException을 전달할 때 SQLException을 넣어서 전달해주는 중첩 예외 방식을 사용하고 있습니다.
중첩예외로 발생시켜줄 경우, 호출하는 쪽에서 Throwable 클래스의 getCause() 메서드로 원인 예외를 확인할 수 있습니다.
RuntimeException 전환
위와 같은 포장(wrap)형 예외 전환 말고, 형태(?)를 바꿔주는 예외 전환 방법이 있습니다.
또 다시 SQLException으로 예를 들어보겠습니다.
SQLException은 체크 예외입니다. 체크 예외는, 해당 예외 발생 가능성이 있는 곳에서 예외의 처리를 문법적으로 강제합니다.
그런데 중요한점은, SQLException의 경우 대부분이 복구 불가능한 예외라는 점입니다.
즉 대부분이 예외를 잡아도 처리해줄수 있는게 없다는 뜻인데… 이럴경우 그냥 throws로 던져버려야 할까요?
호출하는 쪽에서라도 예외를 받아 처리하면 다행이겠지만, SQLException의 경우 호출하는 쪽에서도 딱히 처리할게 없습니다.
결국 무차별 throws와 같은 현상이 발생하게 됩니다… 이는 매우 무의미합니다.
아무리 예외 처리를 넘기고 넘겨봤자 처리가 불가능하기 때문입니다.
어쩌피 이렇게 처리가 안될 예외이면 가능한 빨리 이를 RuntimeException으로 포장하여, 호출하는 쪽에서 무차별 throws를 선언하지 않도록 해주는 것이 좋습니다.
1 | try { |
위와 같이 처리 가능한 SQLExceptoin의 경우 처리해주고,
나머지 예외의 경우 RuntimeException으로 포장하여 호출 메서드들 쪽에서 신경쓰지 않도록 해주는 것이 좋습니다.
대신, 발생시에 로깅이나 메일 전송같은 로직을 발생시켜서 추후에 개발자가 그것을 보고 처리할 수 있도록 하는게 좋습니다.
무작정 throws를 선언하는 것은 올바른 예외처리 방법이 아닙니다.
애플리케이션 예외
이는 위의 RuntimeException 예외 전환과는 반대되는 방식입니다.
시스템 상의 예외가 아닌, 비즈니스 로직에서 발생하는 예외에 대해서는 사용자가 직접 예외를 정의해주기도 합니다.
예를 들자면 잔고가 0인 통장에서 출금을 하려는 경우 등이 있습니다.
적절한 리턴값으로 로직을 구성할 수도 있지만, 리턴값이라는게 표준도 없고 조건문이 많아져서 로직을 파악하기가 더 힘들어집니다.
이럴 경우, 비지니스적인 의미를 가진 예외를 정의하여 발생시켜 주는것이 상대적으로 코드가 더 깔끔해집니다.
(예외를 사용하는 경우 catch 블록에 모아 둘수 있기 때문. 리턴값 사용시 로직 안에서 체크하므로 보기 복잡합니다.)
그리고 이런 예외들은 체크 예외로 만들어서 예외 처리를 강제하도록 합니다.
이런 예외를 보통 애플리케이션 예외 라고 합니다.
여러가지 예외처리 방법에 대해 알아보았지만, 정답은 없습니다. 상황에 맞춰 사용해야 하죠.
잘못된 예외처리는 항상 피하고, 예외처리 방법의 특징을 항상 생각하며 프로그램을 작성해야겠네요…(다짐ㅋㅋ)
스프링 예외처리
스프링을 이용하여 DAO 코드를 작성하면, ex) JdbcTemplate
예외 발생 시 스프링에서 제공하는 예외를 던져줍니다.
스프링은 데이터 관련 작업에서 발생하는 수많은 예외들의 대부분을 추상화하고, 재정의하여 제공하고 있습니다.
일단 먼저 알고 가셔야할 것은, 스프링에서 제공하는 데이터 작업 예외들은 모두 RuntimeException 예외들입니다.
서버상에서 발생하는 SQL 관련 예외들은 대부분이 복구 불가능한 예외이기 때문에, 문법적인 불편함을 제거하기 위해 모두 RuntimeException으로 정의한 것입니다.
이제 추상화를 좀 더 상세하게 살펴보겠습니다.
- 스프링에서는 DB에 독립적인 예외처리가 가능하도록 예외들이 추상화 되어있습니다.
JDBC로 DAO 작성했을 경우를 생각해보시면, 언제나 일관된 예외인 SQLException이 발생했었습니다.
이럴 경우 예외만 가지고는 어떤 예외인지 판별이 안되므로, getErrorCode() 메서드를 호출하여 예외처리를 진행해야 했습니다.
하지만 여기서 문제점은 getErrorCode 메서드 같은 경우, DB 제조사별로 제각각의 에러코드를 반환한다는 점 때문에 DB에 독립적인 프로그래밍이 거의 불가능했습니다.
예외처리부분에서 각 DB 제조사별 에러 코드를 확인하고, 처리해야 했으니까요…
그러나 스프링의 경우 각 DB별로 예외클래스와 에러코드 매핑 파일을 두고, 일관된 예외 클래스로 반환하게 해줍니다.
스프링 라이브러리 파일 중에 jdbc 관련 jar 파일을 풀어서 보시면 안에 sql-error-codes.xml 이라는 파일이 보이실겁니다.
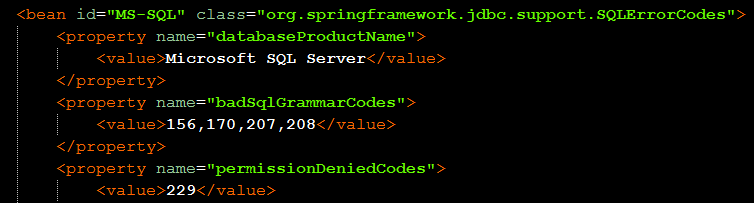
해당 파일을 열어보시면 위와 같이 정의가 되어있습니다.

MySQL도 있고…
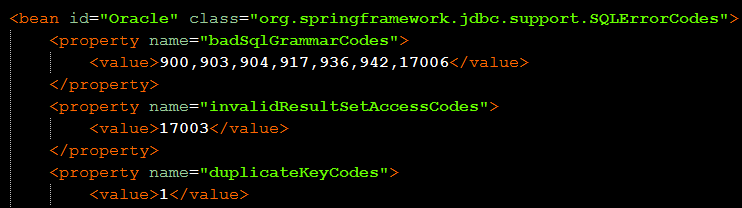
Oracle도 있습니다.
이런식으로 약 10여개 정도 DB의 에러 코드에 대해 모두 매핑이 되어있습니다.
그리고 보다시피, 각 에러코드에 대해 일관된 프로퍼티명으로 정의해뒀음을 보실 수 있습니다.
즉, 스프링을 사용하여 DAO를 작성할 경우, DB가 바뀌더라도 일관된 예외로 받을 수 있게 된다는 의미입니다.
이로 인해 DB에 독립적인 프로그래밍이 가능하게 됩니다.
스프링에서 제공하는 JdbcTemplate를 사용해보시면 DB를 바꾸더라도 SQL 에러 발생시 일관된 예외를 던져주는 것을 보실 수 있을 겁니다.
- 스프링에서는 DAO 구현 기술에 관해서도 독립적인 예외처리가 가능하도록 추상화 되어있습니다.
보통 DAO 작성시, 인터페이스를 통한 전략패턴 형태로 작성합니다.
DAO 작성 기술이 JDBC만 있는 것이 아니기 때문이죠. JDBC, Hibernate, JDO, JPA 등등 굉장히 많습니다.
그리고 여기서 또 문제가 되는것은, 각각 기술에 따라 던져지는 예외 또한 다르다는 것입니다.
JDBC는 SQLException, Hibernate는 HibernamteException, JPA는 PersistenceException… 이런식이죠.
하지만 스프링은 이러한 것조차도 계층적으로 추상화 해두었다는 겁니다… ㄷㄷ
중복키 예외가 발생했을 떄를 예로 들어보면,
JDBC의 경우 DuplicateKeyException, 하이버네이트의 경우 ConstraintViolcationException을 발생시킵니다.
그리고 이 예외들은 공통된 상위 예외로 DataIntegrityViolationException를 가집니다.
즉, 이런식으로 대부분의 모든 예외가 추상화 되어 있기 떄문에, 스프링을 사용하면 DAO의 구현기술, DB의 종류에 독립적인 프로그래밍이 가능해집니다.
하지만… DAO의 구현기술에 관한 추상화는 DB 종류에 관한 추상화보다는 이용가치가 조금 떨어지는 것이 현실입니다.
DataIntegrityViolationException 예외의 경우 중복키 예외외에 다른 제약조건 위반상황에서도 발생하기 때문이죠 ㅠ.ㅠ
스프링의 추상화는 정말 대단하지만… 근본적인 한계 때문에 완벽하다고 기대할순 없습니다.
그래도 스프링은 참 대단하네요. 이정도만 해도 ㄷㄷ
간단히 DuplicateKeyException 계층을 보면 위와 같죠.
빨간색으로 표시한 DataAccessException이 스프링에서 제공하는 예외의 최상위 클래스입니다.
RuntimeException의 하위클래스인것도 볼 수 있네요.
여기까지 예외처리 방법과 스프링의 예외 추상화에 대해 알아보았습니다…
예외라는게 중요하지만 신경 잘 못쓰게되는 부분인 것 같습니다.
책을 통해 공부하고, 포스팅을 함으로써 다시 한번 중요성을 꺠닫는것 같네요…
다른 분들에게도 도움이 되길 바라겠습니다.
감사합니다.