Spring Data JPA는 스프링에서 JPA를 편리하게 사용할 수 있도록 지원하는 프로젝트다.
데이터 접근 계층을 개발할 때 지루하게 반복되는 CRUD 문제를 세련된 방법으로 해결할 수 있게 해준다.
- CRUD 처리를 위한 공통 인터페이스 제공
- 인터페이스만 작성하면 동적으로 구현체를 생성해서 주입해줌
- 따라서 인터페이스만 작성해도 개발을 완료할 수 있음
설정
maven repository에서 Spring Data Jpa 검색해서 gradle에 추가하면 된다.
1 | compile group: 'org.springframework.data', name: 'spring-data-jpa', version: '2.1.2.RELEASE' |
spring boot를 사용할 경우 Spring Boot Data JPA Starter를 사용해주는 것이 좋다.
1 | compile group: 'org.springframework.boot', name: 'spring-boot-starter-data-jpa', version: '2.1.1.RELEASE' |
이후 spring config에 아래와 같이 작성한다.
-
xml config
1
<jpa:repositories base-package="com.joon.repository">
-
java config
1
2
3
(basePackages = "com.joont.repository")
public class AppConfig(){}
이렇게 설정해두면 Spring Data Jpa는 base package에 있는 레파지토리 인터페이스들을 찾아서 해당 인터페이스를 구현한 클래스들을 동적으로 생성한 다음, 빈으로 등록한다.
JpaRepository(공통 인터페이스)
JpaRepository는 앞서 언급했던 CRUD 처리를 위한 공통 인터페이스이다.
이 인터페이스를 상속받은 인터페이스만 생성하면 해당 엔티티에 대한 CRUD를 공짜로 사용할 수 있게된다.
1 | public interface MemberRepository extends JpaRepository<Member, Long>{ |
제네릭에는 엔티티 클래스와 엔티티 클래스가 사용하는 식별자 타입을 넣어주면 된다.
JpaRepository의 계층구조는 아래와 같다.
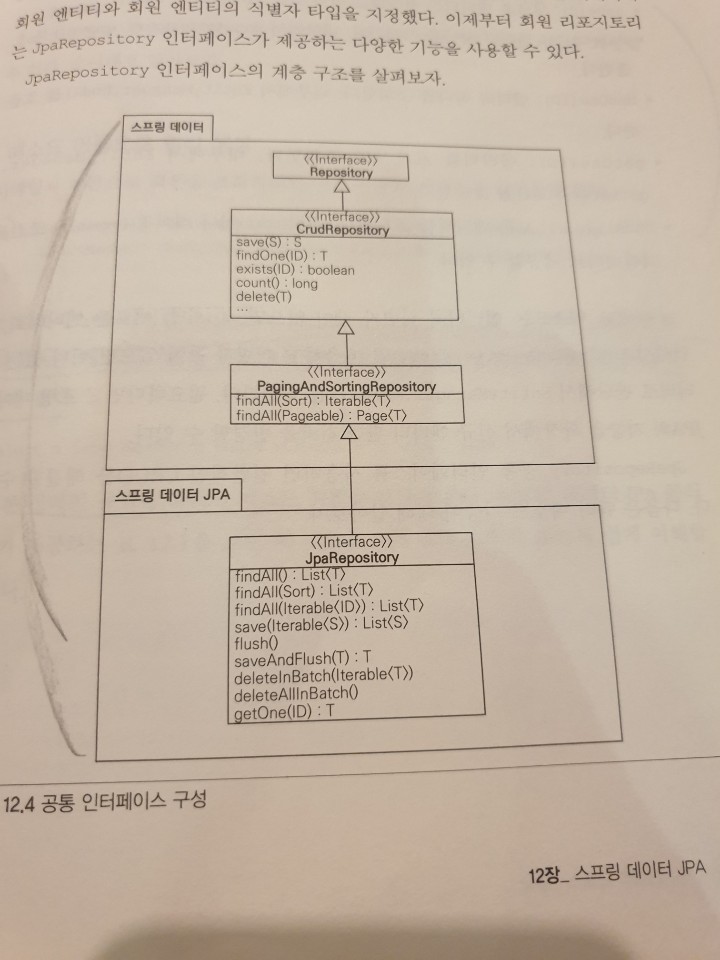
보다시피 스프링 데이터 프로젝트가 공통으로 사용하는 인터페이스를 사용하고
JpaRepository에서 JPA에 특화된 기능을 추가로 제공한다.
실제 구현체
공통 인터페이스인 JpaRespository는 org.springframework.data.jpa.repository.support.SimpleJpaRepository 클래스가 구현한다.
1 | // 1 |
- @Repository 적용
JPA 예외를 스프링이 추상화 한 예외로 변환한다.
- Transactional(readOnly = true) 적용
- 전체적으로 트랜잭션이 적용되어 있다. 이로인해 서비스에서 트랜잭션을 적용하지 않으면 레파지토리에서 트랜잭션을 시작하게 된다.
- 공통 인터페이스에는 조회하는 메서드가 많으므로 전체적으로
readOnly=true를 적용해서 약간의 성능향상을 얻는다.
- Transactional
- 조회 메서드가 아니라서 readOnly=true가 빠지게 한다.
- save
- 보다시피 저장할 엔티티가 새로운 엔티티면 저장하고 이미 있는 엔티티면 병합한다.
- 여기서 사용되는
entityInformation.isNew는 식별자가 객체일때는 null, primitive 타입일때는 0이면 새로운 객체라고 판단한다. Persistable인터페이스를 구현한 객체를 빈으로 등록하면 위의 조건을 직접 정의할 수 있다.
사용
메서드 이름으로 쿼리 생성
인터페이스에 선언한 메서드의 이름으로 적절한 JPQL 쿼리를 생성해주는 마법같은(ㅋㅋ) 기능이다.
1 | public interface MemberRepository extends JpaRepository<Member, Long>{ |
이렇게만 작성하면 Spring Data JPA가 메서드 이름을 분석해서 JPQL을 생성한다.
위의 메서드를 통해 생성되는 JPQL은 아래와 같다.
1 | SELECT m FROM Member m WHERE m.email = ?1 AND m.name = ?2 |
물론 정해진 규칙은 있다.
현재 보니까 생각보다 굉장히 많은 기능을 지원한다.
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repositories.query-methods.details
- findByNameAndEmail 의 형태로 작성.
By뒤부터 파싱 (조건은 여기에) - findDistinctBy 로
distinct가능 - 엔티티 탐색 가능. camel case로 해도 되지만 애매하니 findByAddress_ZipCode 처럼
_로 이어주는게 좋을 듯 - findFirst3By, findTop10By, findFirstBy(1건) 로
limit기능을 사용할 수 있다. findLast3By 같은건 없음 - findByAgeOrderByNameDesc 처럼
order by가능 - findBy 말고 countBy, deleteBy도 있음
반환 타입
Spring Data JPA는 유연한 반환 타입을 지원한다.
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repository-query-return-types
기본적으로 결과가 한건 이상이면 컬렉션 인터페이스를 사용하고, 단건이면 반환 타입을 지정한다.
1 | List<Member> findByMember(String name); // 컬렉션 |
단건의 경우 T 형태와 Optional<T> 형태 2개로 받을 수 있다.
결과가 2건이상 나오면 javax.persistence.NonUniqueResultException 예외가 발생하고,
결과가 0건일 경우 T는 null, Optional<T>는 Optional.empty() 를 리턴한다.
참고로 단건의 경우 내부적으로
query.getSingleResult()를 사용해서 결과가 0건일 경우javax.persistence.NoResultException이 발생해야하지만, 이는 다루기가 까다로우므로 exception을 발생시키지 않는 방향으로 기능을 제공한다.
Named Query
엔티티나 xml에 작성한 Named Query도 찾아갈 수 있다.
1 |
|
Spring Data JPA는 메서드 이름으로 쿼리를 생성하기 전에 해당 이름의 Named Query를 먼저 찾는다(전략 변경 가능)
도메인 클래스 + .(점) + 메서드 이름으로 먼저 찾고, 없으면 JPQL을 생성한다.
위의 상황에서는 Member.findByName Named Query를 찾게 된다.
JPQL 직접 정의
org.springframework.data.jpa.repository.Query 어노테이션을 사용하면 된다.
1 | // 위치기반 파라미터 |
아무리봐도 위치기반 파라미터는 개극혐이다.
내 주변사람에는 위치기반 파라미터를 쓰는 사람이 없으면 좋겠다.
네티티브 쿼리도 사용할 수 있다. nativeQuery = true 옵션만 주면 된다.
1 | public interface MemberRepository extends JpaRepository<Member, Long>{ |
네이티브 쿼리는 위치기반 파라미터가 0부터 시작한다.
벌크 연산
1 | public interface MemberRepository extends JpaRepository<Member, Long>{ |
@Modifying을 명시해줘야 한다.
기존 벌크 연산처럼 영향받은 엔티티의 개수를 반환한다.
알다시피 벌크 연산은 영속성 컨텍스트를 무시한다.
벌크 연산후에 영속성 컨텍스트를 초기화하고 싶으면 clearAutomatically 옵션을 true로 주면 된다. 기본값은 false이다.
1 | (clearAutomatically = true) |
페이징과 정렬
아래의 두 파라미터를 사용하면 쿼리 메서드에 페이징과 정렬 기능을 추가할 수 있다.
org.springframework.data.domain.Sort: 정렬기능org.springframework.data.domain.Pageable: 페이징기능(Sort 포함)
사용법은 간단하다. 위의 두 클래스를 파라미터에 사용하기만 하면 된다.
Pageable을 사용하면 반환타입으로 Page를 받을 수 있다.
해당 클래스를 사용하면 페이징과 관련된 다양항 정보들을 얻을 수 있다. 참고로 Page를 반환타입으로 받으면 전체 데이터 건수를 조회하는 count 쿼리가 추가로 날라간다.
1 | public interface Page<T> extends Slice<T> { |
아래는 간단한 사용 예제이다.
1 | // Pageable은 interface 이므로 구현체인 PageRequest 를 사용해야 한다. |
컨트롤러에서 사용
-
Pageable 객체를 Controller parameter로 직접 받을수도 있다
1
2
3
4("/members")
public String list(Pageable pageable){
// ...
}1
/members?page=0&limit=10&sort=name,asc&sort=age,desc
pageable 기본값은
page=0, size=20이다.
정렬을 추가하고 싶으면 sort 파라미터를 계속 붙여주면 된다. -
페이징 정보가 둘 이상이면 접두사를 사용해서 구분할 수 있다
1
2
3
4
5
6("/members")
public String list(
@Qualifier("member") Pageable memberPageable,
@Qualifier("order")Pageable orderPageable){
// ...
}1
/members?member_page=0&order_page=1
사용자 정의 레파지토리 구현
Spring Data JPA로 개발하면 인터페이스만 정의하고 구현체는 만들지 않는데, 다양한 이유로 메서드를 직접 구현해야 할 때도 있다.
그렇다고 레파지토리 자체를 직접 구현하면 공통 인터페이스가 제공하는 모든 기능까지 다 구현해야 한다.
Spring Data JPA는 이런 문제를 우회해서 필요한 메서드만 구현할 수 있는 방법을 제공한다.
-
먼저 사용자가 직접 구현할 메서드를 위한 정의 인터페이스를 작성한다.
1
2
3public interface MemberRepositoryCustom{
public List<Member> search();
} -
위의 사용자정의 인터페이스를 구현한 클래스를 작성한다.
이떄 클래스 이름은레파지토리 인터페이스 이름 + Impl로 지어야한다.
이렇게 해야Spring Data JPA가 사용자 정의 구현 클래스로 인식한다.1
2
3
4
5
6public class MemberRepositoryImpl implements MemberRepositoryCustom{
public List<Member> search(){
// ....
}
}이 클래스 이름 규칙은 변경할 수 있다.
config에 설정했던 spring data jpa 설정의 속성값인repository-impl-postfix값을 지정해주면 된다. 기본값은 Impl 이다.1
(basePackages = "com.joont.repository", repositoryImplementationPostfix = "impl")
-
마지막으로 레파지토리 인터페이스에서 사용자정의 인터페이스를 상속받으면 된다.
1
2
3public interface MemberRepository extends JpaRepository<Member, Long>, MemberRepositoryCustom{
}
spring data jpa + QueryDSL
spring은 2가지 방법으로 QueryDSL을 지원하지만,
하나는 기능에 조금 한계가 있어서 다양한 기능을 사용하려면 JPAQuery를 직접 사용하거나 Spring Data JPA가 제공하는 QueryDslRepositorySupport를 사용하면 된다.
아래는 사용 예제이다.
코드를 직접 써야하므로 사용자 정의 레파지토리를 구현해야한다.
1 | public class OrderRepositoryImpl extends QueryDslRepositorySupport implements OrderRepositoryCustom { |
QueryDslRepositorySupport 클래스를 상속받아서 사용하고 있다.
참고로 생성자에서 QueryDslRepositorySupport에 클래스 정보를 넘겨줘야 한다.
기존에 생성하기 나름 번거로웠던 JPAQuery, JPAUpdateClause, JPADeleteClause 등을 간단하게 생성할 수 있다.
참고로 반환은 전부 인터페이스 타입인 JPQLQuery, UpdateClause, DeleteClause 등을 반환한다.
이 외에도 EntityManager, QueryDSL헬퍼 등을 반환하는 메서드도 구현되어 있다.
QueryDSL에 Pageable 적용하기
QueryDslRepositorySupport를 사용하면 Spring Data JPA의 Pageable을 간단하게 적용할 수 있다.
1 | QItem item = QItem.item; |
Page를 리턴함으로써 완벽하게 Pageable을 사용할 수 있다.